18 May 2017
Le 2 juillet, nous étions à Anime Expo, Los Angeles ! Voir les slides.
Car oui, nous avons été acceptés pour faire une présentation à la conférence académique d’Anime Expo.
Everyone regularly ask themselves what movie, series or book they
should watch next, according to their taste. Mangaki wants to innovate
access to Japanese culture by providing a unique user experience
through a recommender system.
When a user shows up, Mangaki asks them to rate a few works. Based on
their answers, they receive tailored anime recommendations. Mangaki’s
machine learning techniques attempt to “guess” the taste of new users,
by geometrically positioning their ratings within those collected from
other users. Indeed, we will show that a simple factor analysis on the
anonymized data (325,000 ratings from 2,220 users and 15,000 works)
can reveal interesting and counterintuitive categories of manga that
are liked together.
Mangaki started as a French student project in 2014 (it is so much fun
to conduct research when it is unleashed on real data!). It received a
prize from Microsoft (2015) and the Japanese Cultural Institute in
Paris (2016): we won a trip to Tokyo to meet Japanese companies and
investors, who were surprised to learn that we wanted to stay
non-profit. The founder now holds a PhD in CS and works as a
researcher in RIKEN, Tokyo.
In its mission to promote transparency and education, all the code of
the Mangaki platform is open source. Consequently, it becomes possible
for anyone to understand better the algorithms behind recommender
systems. We regularly hold conferences for students, from high school
to master’s degree.
The Mangaki dataset will also be released for academic purposes
(humanities: dōzo!), while respecting the users’ privacy. We are
currently organizing a data challenge with Kashima’s Machine Learning
Lab in Kyoto University, where students will have to improve the
accuracy of the recommendations. There is plenty of exciting research
yet to be made, notably the automatic detection of NSFW posters using
deep learning.
Know more: presentation.pdf
Demo: MP4
21 Apr 2017
You can run our 5-fold cross validation on the Movielens dataset.
Download the Movielens dataset prepared by our team:
Clone the GitHub repo and:
git clone git@github.com:mangaki/mangaki.git
cd mangaki
python3 -m venv venv
. venv/bin/activate
pip install -r requirements.txt
pip install -r requirements/dev.txt
# Put the ratings-ml.csv file in the data folder
cd mangaki
cp settings.template.ini settings.ini
./manage.py compare movies
It will run everything and display:
Final results
als-20: RMSE = 1.122326
svd-20: RMSE = 1.157234
Feel free to modify the mangaki/mangaki/management/commands/compare.py file to compare more algorithms.
27 Oct 2016
Je m’intéresse aux in-flight entertainment systems.
As these systems evolve, recommendations could become more sophisticated. “For example, [the system could say,] ‘The last time you were on board, you watched this movie, but you didn’t finish it. Would you like to finish it now?’” Rhoads suggests. “We can say: ‘The last 15 movies that you watched on flights for the past two months have been around these characters or themes. Here are recommendations from this month’s movie selections.’ These are things that are relatively easy to implement and we’re already seeing some in our companion app.”
Il faut les contacter !
Rhoads expects in-flight connectivity to revolutionize recommendations in the future. “Where it’s going to get interesting is the airline’s ability to use connectivity to the aircraft to load content dynamically, based on passenger experience or passenger requests,” he says.
Contact : Fabienne Regitz, IFE product manager for Lufthansa.
The companion app carries passenger-viewing data from one flight to the next to inform recommendations.
Contact : Cedric Rhoads, executive director, Corporate Sales and Product Management at Panasonic Avionics.
“We are able to see how individual content files … are performing each month and then use that information to curate the next cycle’s content set” – Megan Worley, American Airlines
Apparemment Panasonic ont leur propre système appelé eX2 qui est utilisé par Emirates, Singapore Airlines, Cathay Pacific Airways et qui a remporté en 2007 un prix de la World Airline Entertainment Association, à présent appelée Airline Passenger Experience Association. C’est une surcouche de Red Hat, je crois.
“We’re very proud of our customers,” says Paul Margis, CEO of Panasonic Avionics. “Each one has a very unique system.”
Nouveau, 25 octobre 2016
Emirates has selected Thales’ AVANT in-flight entertainment (IFE) solution for its fleet of 150 Boeing 777X aircraft.
Source : Thales’ AVANT IFE Platform to Foster Innovation on Emirates Boeing 777X Fleet
Donc apparemment il y a Panasonic, Thales et Zodiac Aerospace, ce dernier est open source développé par Open Wide racheté par Smile.
Sur une autre note, un mémoire (de master je crois) d’un Portugais à Amadeus (Sophia-Antipolis) : Design and Implementation of a Flight Recommendation Engine. Mais c’est différent, c’est pas pour les in-flight entertainment.
Idées
- Contacter Fabienne Regitz de Lufthansa, ainsi que l’auteur des articles sur apex.aero pour lui dire ce qu’on fait.
- Contacter Thalès.
Autre
11 May 2016
Vous connaissez le principe, un utilisateur s’inscrit, rentre ses préférences, le système lui recommande des œuvres susceptibles de lui plaire.

Particularités de mangaki.fr
- Les notes : j’adore / j’aime / neutre / je n’aime pas / je veux voir / je ne veux pas voir
- On peut vous recommander des mangas même si vous n’avez noté que des séries animées
Plus proches voisins (KNN)
Principe. Trouver des utilisateurs qui vous ressemblent en matière de goûts pour vous recommander ce qu’ils ont aimé que vous n’avez pas vu.
- Quelles valeurs assigner à chaque rating (
favorite, like, willsee, etc.) ?
- Combien de voisins choisir ? Pour estimer la valeur d’une œuvre, faut-il considérer les 15 plus proches voisins ayant noté cette œuvre ? C’est ce que @Karypis2008 conseille.
Voir le code de la KNN sur GitHub
SVD
Principe. Trouver des profils types et répartir les utilisateurs selon cette base de profils types.
- Comment considérer les entrées manquantes ? On les replace par la moyenne.
- Avantage : on peut construire le Top 8000 d’un individu.
Voir le code de la SVD sur GitHub, depuis scikit-learn
De l’intérêt de la fonction d’erreur
- Quelle fonction d’erreur choisir ? La RMSE ou simplement compter le nombre de faux positifs et négatifs ? Dans @Karypis2008, ils suggèrent plutôt une sorte d’Expected Utility qui pénalise plus les faux positifs que les faux négatifs.
11 May 2016
C’est bien beau d’avoir un moteur de recommandation mais encore faut-il l’alimenter (le bootstrapper) avec un test de bienvenue : un nouvel utilisateur ne sait pas quoi noter.
Quels œuvres lui présenter de façon à obtenir en peu de questions une idée de ses goûts ? Il faut des œuvres controversées, mais populaires.
Démarrage à froid d’utilisateur
Bootstrapper un KNN
@Karypis2008 suggère de faire un k-means, où la fonction de cluster est la fonction de voisinage, puis d’ensuite essayer de trouver l’œuvre qui va permettre d’identifier le plus précisément possible le cluster dont l’utilisateur fait partie (donc, ses plus proches voisins). Donc ils font un arbre de décision qui maximise la réduction d’entropie de la distribution du groupe courant parmi les clusters.
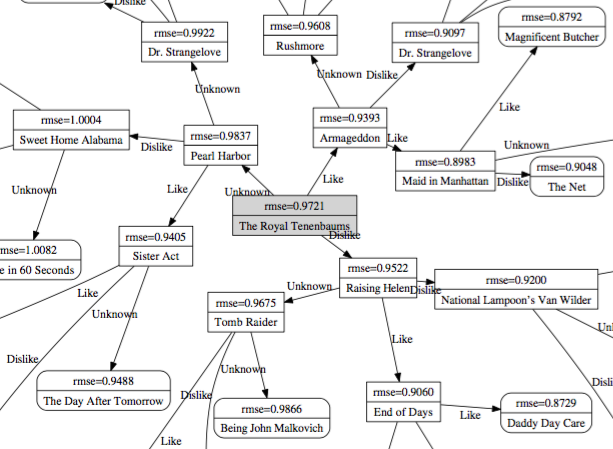
Bootstrapper une SVD
J’aime bien l’approche de @Golbandi2001 : faire un arbre de décision en choisissant des œuvres qui trisectent au mieux selon la réponse « Like / Hate / Unknown », ça permet d’avoir un joli compromis entre populaire et controversé. Plus précisément, ils s’intéressent à trouver l’œuvre qui minimise la quantité MSE(ceux qui ont aimé) + MSE(ceux qui ont détesté) + MSE(ceux qui ne connaissent pas). On a essayé sur Mangaki mais on se fait un peu avoir à cause des Unknown.
Une autre approche dans @Gabillon2014 consiste à faire des épisodes test / recommandation / test / recommandation pour présenter de façon adaptative (test) k œuvres à noter de façon à maximiser les éléments suggérés (recommandation) qui seront proches de quelque chose que le newcomer a liké. Ils donnent un reward de 1 si la recommandation est proche d’un film liké par l’utilisateur, et un reward de 0.1 si la recommandation est proche d’au moins un film noté par l’utilisateur mais qu’aucun d’entre eux n’a été liké par l’utilisateur.
Mesurer la culture du nouvel utilisateur
On pourrait imaginer un test adaptatif à la modèle de Rasch (ce qu’ils utilisent pour le GMAT et PISA pour estimer le « score de culture » du nouveau venu, juste en demandant : « Et ça, tu connais ? — Ouais mais j’aime pas. »
Démarrage à froid d’œuvre
De façon similaire, comment faire lorsqu’une nouvelle œuvre rejoint la base de données afin d’avoir une petite idée de sa qualité ?
Ça c’est superbe mais pas encore adaptatif : @Anava2015 remarque que dans une SVD, la RMSE à la fin est une fonction supermodulaire. Donc ils cherchent l’ensemble de k œuvres qui va réduire la RMSE au mieux, en prouvant que le glouton se débrouille pas trop mal (à 1 - 1/e de l’optimal, c’est-à-dire 63 %).