Démarrage à froid
11 May 2016C’est bien beau d’avoir un moteur de recommandation mais encore faut-il l’alimenter (le bootstrapper) avec un test de bienvenue : un nouvel utilisateur ne sait pas quoi noter.
Quels œuvres lui présenter de façon à obtenir en peu de questions une idée de ses goûts ? Il faut des œuvres controversées, mais populaires.
Démarrage à froid d’utilisateur
Bootstrapper un KNN
@Karypis20081 suggère de faire un k-means, où la fonction de cluster est la fonction de voisinage, puis d’ensuite essayer de trouver l’œuvre qui va permettre d’identifier le plus précisément possible le cluster dont l’utilisateur fait partie (donc, ses plus proches voisins). Donc ils font un arbre de décision qui maximise la réduction d’entropie de la distribution du groupe courant parmi les clusters.
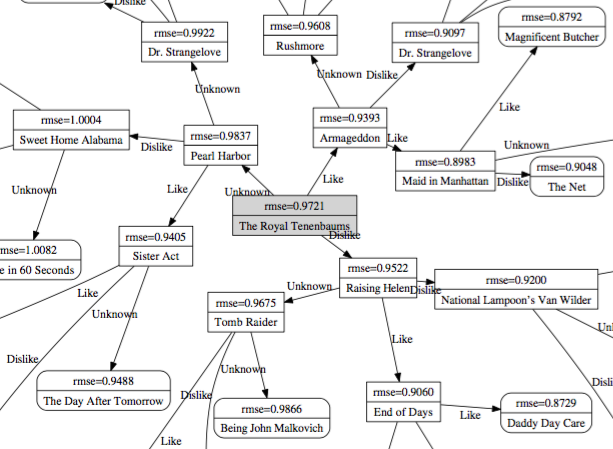
Bootstrapper une SVD
J’aime bien l’approche de @Golbandi20012 : faire un arbre de décision en choisissant des œuvres qui trisectent au mieux selon la réponse « Like / Hate / Unknown », ça permet d’avoir un joli compromis entre populaire et controversé. Plus précisément, ils s’intéressent à trouver l’œuvre qui minimise la quantité MSE(ceux qui ont aimé) + MSE(ceux qui ont détesté) + MSE(ceux qui ne connaissent pas). On a essayé sur Mangaki mais on se fait un peu avoir à cause des Unknown.
Une autre approche dans @Gabillon20143 consiste à faire des épisodes test / recommandation / test / recommandation pour présenter de façon adaptative (test) k œuvres à noter de façon à maximiser les éléments suggérés (recommandation) qui seront proches de quelque chose que le newcomer a liké. Ils donnent un reward de 1 si la recommandation est proche d’un film liké par l’utilisateur, et un reward de 0.1 si la recommandation est proche d’au moins un film noté par l’utilisateur mais qu’aucun d’entre eux n’a été liké par l’utilisateur.
Mesurer la culture du nouvel utilisateur
On pourrait imaginer un test adaptatif à la modèle de Rasch (ce qu’ils utilisent pour le GMAT et PISA pour estimer le « score de culture » du nouveau venu, juste en demandant : « Et ça, tu connais ? — Ouais mais j’aime pas. »
Démarrage à froid d’œuvre
De façon similaire, comment faire lorsqu’une nouvelle œuvre rejoint la base de données afin d’avoir une petite idée de sa qualité ?
Ça c’est superbe mais pas encore adaptatif : @Anava20154 remarque que dans une SVD, la RMSE à la fin est une fonction supermodulaire. Donc ils cherchent l’ensemble de k œuvres qui va réduire la RMSE au mieux, en prouvant que le glouton se débrouille pas trop mal (à 1 - 1/e de l’optimal, c’est-à-dire 63 %).
-
@Karypis2008 Information Gain through Clustered Neighbors, dans Learning preferences of new users in recommender systems: an information theoretic approach, ACM SIGKDD 2008. ↩
-
@Golbandi2011 Adaptive bootstrapping of recommender systems using decision trees, WSDM 2011 (salaud de paywall). ↩
-
@Gabillon2014 Large-Scale Optimistic Adaptive Submodularity, AAAI 2014. ↩
-
@Anava2015 Budget-constrained item cold-start handling in collaborative filtering recommenders via optimal design, WWW 2015. ↩