Mangaki Data Challenge, version française
18 Jul 2017(also in English / 日本語)
Mangaki.fr est un site Web où les utilisateurs peuvent noter des anime et des mangas et recevoir des recommandations personnalisées (quel anime faut-il que vous regardiez absolument ?). Le site est développé par une association principalement composée d’étudiants, et tout le code de la plateforme est disponible sur GitHub, donc quiconque souhaitant améliorer le site peut contribuer librement.
Dans ce challenge, afin de gagner (et montrer votre suprématie au monde entier), vous devrez prédire les préférences d’utilisateurs sur des anime qu’ils n’ont pas vus. Les notes sont fournies par d’authentiques utilisateurs de Mangaki.
Il est plus que conseillé d’utiliser d’autres sources d’information que les données qu’on vous fournit pour améliorer votre score. Tous les langages sont acceptés, vous êtes donc libres d’utiliser celui que vous préférez ! Les gagnants pourront décrire leur solution sur University of Big Data.
Participer au Mangaki Data Challenge !
Types de notes anime/manga
Sur Mangaki, les utilisateurs peuvent noter les anime ou manga de la façon suivante :
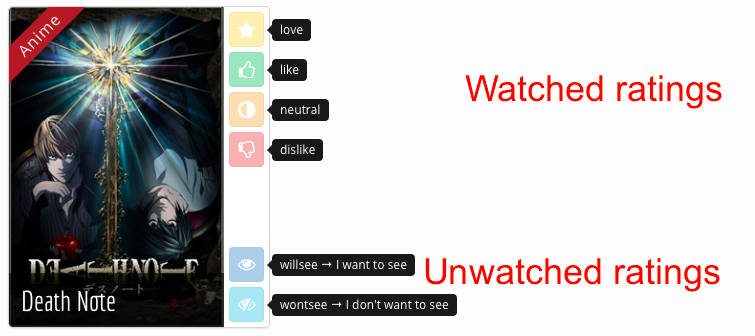
Ainsi, soit un utilisateur a vu (ou lu) une œuvre, auquel cas la note attribuée à cette œuvre est l’une de celles-ci :
love: j’ai adoré ;like: j’ai aimé ;neutral: je n’ai ni aimé, ni pas aimé ;dislike: je n’ai pas aimé.
Soit l’utilisateur n’a pas vu (ou lu) une œuvre, auquel cas la note attribuée à cette œuvre est :
willsee(ou1): j’ai envie de voir (ou lire);wontsee(ou0): je n’ai pas envie de voir (ou lire).
Données d’entraînement : train.csv
Le jeu de données d’entraînement, train.csv, contient les informations suivantes :
user_id,work_id,rating
50,4041,0
508,1713,0
1780,7053,1
658,8853,0
1003,9401,0
...
où chaque ligne <user_id>,<work_id>,<rating> contient :
user_id: l’ID d’un utilisateur, entre 0 et 1982 ;work_id: l’ID d’un anime ou manga, entre 0 et 9896 ;rating: l’une des valeurs suivantes :1(willsee) ou0(wontsee).
Par exemple, 1780,7053,1 signifie que l’utilisateur no 1780 n’a pas vu l’œuvre no 7053, mais a envie de la voir.
Données d’évaluation : test.csv
Le jeu de données d’évaluation, test.csv, contient les informations suivantes :
user_id,work_id
486,1086
1509,3296
617,1086
270,9648
459,3647
...
où chaque ligne <user_id>,<work_id> contient :
user_id: l’ID d’un utilisateur, entre 0 et 1982 ;work_id: l’ID d’une œuvre anime ou manga, entre 0 et 9896.
Pour participer, vous devrez écrire un programme qui devine les notes manquantes. Ainsi, votre programme devra produire un fichier submission.csv de la forme suivante :
user_id,work_id,prob_willsee
486,1086,XXX
1509,3296,XXX
617,1086,XXX
270,9648,XXX
459,3647,XXX
...
où XXX désigne la probabilité d’obtenir une note willsee pour la paire user_id, work_id correspondante. Votre fichier sera utilisé pour l’évaluation.
Si vous étiez laissé dans la jungle seulement avec ces informations, le problème serait sacrément difficile. Heureusement pour vous, nous fournissons un jeu de données supplémentaire.
Jeu de données bonus : watched.csv
Le jeu de données watched.csv contient les informations suivantes :
user_id,work_id,rating
717,8025,dislike
1106,1027,neutral
1970,3949,neutral
1685,9815,like
1703,3482,like
...
où chaque ligne <user_id>,<work_id>,<rating> contient :
user_id: l’ID d’un utilisateur, entre 0 et 1982 ;work_id: l’ID d’un anime ou manga, entre 0 et 9896 ;rating: l’une des valeurs suivantes :love,like,neutraloudislike.
Par exemple, 717,8025,dislike signifie que l’utilisateur no 717 n’a pas aimé l’œuvre no 8025.
Évaluation
Comme mesure pour départager les soumissions, le score AUC sera utilisé.
Dans le classement public, les scores intermédiaires sont calculés en utilisant 50 % du jeu de données de test, et les scores finaux seront calculé en utilisant les 50 % restants. Le classement final sera déterminé en fonction des scores finaux.
Téléchargez les données et participez au concours sur University of Big Data !