Mangaki Data Challenge, English version
18 Jul 2017(en français / 日本語)
Mangaki.fr is an online platform where users can provide ratings of anime and manga and receive personalized recommendations of what to watch next. It is being actively developed by a community of French crazy students, and the whole code of the platform is available on GitHub, so interested users can improve the machine learning algorithms of Mangaki.
In this challenge, in order to win (and show your supremacy to the world), you will have to predict the ratings of users over unwatched anime and manga. The ratings are provided by the actual Mangaki users.
You are more than welcome to look for extra sources of data in order to improve your score. All programming languages are allowed. Just find the one that works best for you! Winners will be provided an opportunity to promote their solutions on University of Big Data.
Types of anime/manga ratings
On Mangaki, users can rate anime or manga the following way:
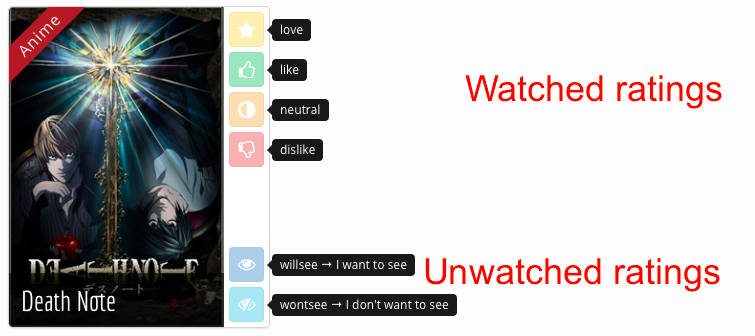
Which means either they watched (or saw) the work, in which case the rating can be one of these watched ratings:
love: they loved it;like: they liked it;neutral: neither they liked it or disliked it;dislike: they did not like it.
Either they did not watch (or see) the work, in which case the rating can be one of these unwatched ratings:
willsee(or1): they stated they want to watch (or read) it;wontsee(or0): they stated they do not want to watch (or read) it.
Train Dataset: train.csv
The train dataset, train.csv, contains the following information:
user_id,work_id,rating
50,4041,0
508,1713,0
1780,7053,1
658,8853,0
1003,9401,0
...
where each line <user_id>,<work_id>,<rating> is composed of:
user_id: the ID of a user, between 0 and 1982;work_id: the ID of an anime or manga, between 0 and 9896;rating: one of the following values:1(willsee) or0(wontsee).
For example, 1780,7053,1 means that the user #1780 didn’t see work #7053, but said they want to see it.
Test Dataset: test.csv
The test dataset, test.csv, contains the following information:
user_id,work_id
486,1086
1509,3296
617,1086
270,9648
459,3647
...
where each line <user_id>,<work_id> is composed of:
user_id: the ID of a user, between 0 and 1982;work_id: the ID of an anime or manga, between 0 and 9896.
To complete a submission, you will have to program an algorithm that guesses those missing ratings. Therefore, your program will have to output a file submission.csv of the following form:
user_id,work_id,prob_willsee
486,1086,XXX
1509,3296,XXX
617,1086,XXX
270,9648,XXX
459,3647,XXX
...
where XXX designates the probability of getting a willsee rating for the corresponding pair user_id–work_id. Your file will be used for evaluation.
If you were left in the wilderness with this, the problem would be quite difficult. Fortunately for you, we provide a bonus dataset.
Bonus Dataset: watched.csv
The bonus dataset watched.csv contains the following information:
user_id,work_id,rating
717,8025,dislike
1106,1027,neutral
1970,3949,neutral
1685,9815,like
1703,3482,like
...
where each line <user_id>,<work_id>,<rating> is composed of:
user_id: the ID of a user, between 0 and 1982;work_id: the ID of an anime or manga, between 0 and 9896;rating: one of the following values:love,like,neutralordislike.
For example, 717,8025,dislike means that the user #717 did not like the work #8025.
Evaluation
As a metric to rank submissions, the AUC score will be used.
In the leaderboard, the intermediate scores are calculated using 50% of the test dataset, and the final scores are calculated using the other 50%. Final ranks are determined according to the final scores.
Download the data and compete now on University of Big Data!